

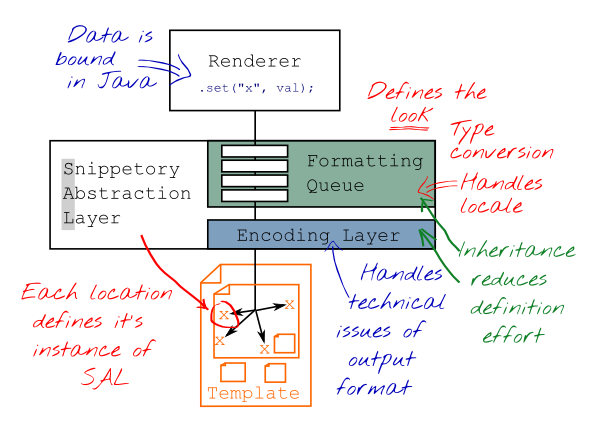
Encodings
The purpose of an encoding is to ensure the syntactical correctness of an output by escaping terms or characters with special meaning in the syntax of the output file. For example the ampersand is illegal within XML as it's used to mark an entity. It has to be replaced by &.
By handling those technical issues of the output file within the template definition the handling logic gets more reusable. And simpler to implement. This is a simple but efficient abstraction layer.
As the encoding is inherited throughout the tree of snippets within a template a single place to define the encoding is sufficient for many cases. However, combination of encodings is common as well. This is why it can be overwritten as often as needed, for entire subtrees or just for single leaf nodes.
If one wants to render data, that won't need to be encoded, most likely because it already is, just wrap in an encoded container. Encodings have a wrap method for this:
tpl.set("x", Encodings.HTML.wrap("<b>markup</b>"));
Trans-coding
When it's defined how the data is already encoded, Snippetory is able to figure out whether it's possible to trans-code to the required encoding, or if there is no appropriate way, to fail immediately. The encoding support in Snippetory is based on not encoded data and encoded containers. (Templates are encoded containers.) Now, if we try to combine to encoded containers, things stay easy as long as they are encoded the same way. The contained data is copied verbatim. But if the encodings are different this difference is tried to resolve by trans-coding. Trans-coding is a 2-phase process. First the overwrites are searched for a specific trans-coding for this specific combination of encodings. If one is found it'll do the job. If not the trans-code method of the target encoding is called. If the trans-coding is unable to resolve the difference an IncompatibleEncodingException is thrown.
Encoding and Transcodings can be registered via Encoding.register().
The Snippetory templating platform ships with a number of predefined Encodings:
- xml
-
It's assumed that Snippetory is used in a modern Unicode based environment. Only a minimal escaping is done:
As XML is a compound format, i.e. it can contain other formats, almost each other will be placed within without any trans-coding. Only on plain text the normal escaping is applied.< --> < & --> & - html
- HTML is derived from XML. It just converts line breaks to <br />-tags to enable transporting of simple formatting within the data bound. Be aware: this applies to data bound, not to some kind of source code like in HTML pages, so we do not break with the good practice of separating the layout of source code, and it's resulting appearance.
- url
- Applies URL encoding to the data
- string
- Most C-based languages have almost the same rules. This fits at least Java and JavaScript.
- html_string
- In JavaScript I've sometimes data that is transported in a string before it's displayed as HTML.
- plain
- Plain text. Not yet encoded data is considered plain. So it can be transcoded to all other encodings.
- NULL
- The wild card encoding. Fits to any other, any other fits to this. Sometimes it's necessary to work around the checks. It's used if no encoding is defined and basically turn off the encoding support.
